Appearance
JMeter进阶篇
逻辑控制器
通过参数化可以实现单个接口的功能测试,而接口测试过程中,除了单个接口的功能测试之外,还会测试接口业务实现,所谓业务,就是一套完整的业务逻辑或流程,这就必须要使用到逻辑控制和关联。
if逻辑控制器
- 测试计划 - 添加 - 配置元件 - 用户定义的变量
- val: future-weaver
- 测试计划 - 添加 - 线程(用户) - 线程组
- 线程组 - 添加 - 逻辑控制器 - if控制器
- if控制器 - 添加 - 取样器 - HTTP请求
- 取消Interpret取消勾选
- 条件: "${val}" == "future-weaver"
- 测试计划 - 添加 - 监听器 - 察看结果树
foreach逻辑控制器
- 测试计划 - 添加 - 配置元件 - 用户定义的变量
name_1:javaname_2:pythonname_3:测试
- 测试计划 - 添加 - 线程(用户) - 线程组
使用初始设置即可- 线程数: 1
- Ramp-Up时间(秒): 1
- 循环次数: 1
- 线程组 - 添加 - 逻辑控制器 - foreach控制器
- 输入变量前缀:
name - 开始循环字段(不包含): 0
- 结束循环字段(包含): 3
- 输出变量名称: val
- 数字之前加上下划线: 勾选
- 输入变量前缀:
- foreach控制器 - 添加 - 取样器 - HTTP请求
- 测试计划 - 添加 - 监听器 - 察看结果树
循环逻辑控制器
- 测试计划 - 添加 - 线程(用户) - 线程组
使用初始设置即可- 线程数: 1
- Ramp-Up时间(秒): 1
- 循环次数: 1
- 线程组 - 添加 - 逻辑控制器 - 循环控制器1
- 循环次数: 10
- 循环控制器1 - 添加 - 取样器 - HTTP请求1
- 线程组 - 添加 - 逻辑控制器 - 循环控制器2
- 循环次数: 5
- 循环控制器2 - 添加 - 取样器 - HTTP请求2
- 测试计划 - 添加 - 监听器 - 察看结果树
关联
XPath提取器
XPath与CSS的区别
XPath和CSS是两种不同的方法,用于在HTML页面中定位和选择元素。它们有一些相似之处,但也有一些显著的区别:
语法:
- XPath使用一种基于XML文档结构的语法来定位元素。它允许您遍历文档树并根据元素的层次结构或属性来定位元素。
- CSS选择器使用一种类似CSS样式表的语法来选择元素。它通常更简洁和直观,因为它基于元素的类名、ID、标签名等属性。
定位能力:
- XPath在元素的定位方面更加灵活和强大。您可以使用XPath来查找相对较复杂的元素结构,例如查找父元素、兄弟元素或子元素等。
- CSS选择器通常更适合简单的元素选择。它在选择元素的能力上不如XPath强大。
性能:
- 通常来说,CSS选择器的性能比XPath要好。因为XPath的解析和匹配过程相对复杂,可能会导致较慢的页面加载速度,特别是在大型文档中。
- CSS选择器通常更快速,因为它更直接地映射到浏览器的渲染引擎。
浏览器支持:
- 大多数现代浏览器都支持XPath和CSS选择器,但在一些特定情况下,可能会出现差异。通常,CSS选择器在各种浏览器中的兼容性更好。
为什么要勾选Use Tidy
在 JMeter 中,XPath Extractor 和 XPath2 Extractor 是两个不同的提取器,而 "use tidy" 选项是用于指定是否要使用 Tidy 解析器来处理 HTML 文档的选项。
Tidy 是一个开源的HTML解析器和修复工具,它用于清理和修复不合法的HTML。当你勾选 "use tidy" 选项时,XPath Extractor 会尝试使用 Tidy 解析器来处理HTML文档,以确保HTML文档是有效的。这对于处理不规范的HTML文档或包含错误的HTML文档非常有用,因为Tidy可以尝试修复文档中的问题,使其更容易解析。
然而,XPath2 Extractor 并没有提供 "use tidy" 选项,因为它是为处理更复杂的XML和XPath 2.0表达式而设计的。通常,XML文档较为严格,因此不像HTML文档那样经常需要修复。此外,XPath2 Extractor 更专注于XPath 2.0语法的支持,因此不包括HTML清理和修复的功能。
因此,是否使用 "use tidy" 取决于您处理的文档类型以及您的需求。如果您处理的是HTML文档,并且文档可能包含错误,那么勾选 "use tidy" 可能是一个好主意。如果您处理的是较为严格的XML文档,您可以使用XPath2 Extractor 而不必担心 "use tidy"。
- 测试计划 - 添加 - 线程(用户) - 线程组
使用初始设置即可- 线程数: 1
- Ramp-Up时间(秒): 1
- 循环次数: 1
- 线程组 - 添加 - 取样器 - HTTP请求1
- HTTP请求1 - 添加 - 后置处理器 - XPath提取器
- Use Tidy: 勾选
- 引用名称: val
- XPath Query:
//title - 匹配数字【0代表随机,-1代表所有】: -1
- 缺省值:
future-weaver
- 线程组 - 添加 - 取样器 - HTTP请求2
https://www.baidu.com/s?wd=${val}
- 测试计划 - 添加 - 监听器 - 察看结果树
正则表达式提取器
- 测试计划 - 添加 - 线程(用户) - 线程组
使用初始设置即可线程数:1Ramp-Up时间(秒):1循环次数:1
- 线程组 - 添加 - 取样器 - HTTP请求1
- HTTP请求1 - 添加 - 后置处理器 - 正则表达式提取器
引用名称:val正则表达式:"dep_name":"(.*?)"?代表不贪婪,去掉?代表贪婪模板:$1$匹配数字【0代表随机,-1代表所有】: -1缺少值:future-weaver
- 线程组 - 添加 - 取样器 - HTTP请求2
https://www.baidu.com/s?wd=${val}
- 测试计划 - 添加 - 监听器 - 察看结果树
跨线程组传值
- 测试计划配置
- 独立运行每个线程组(例如在一个组运行结束后启动下一个): 勾选
- 测试计划 - 添加 - 线程(用户) - 线程组1
使用初始设置即可- 线程数: 1
- Ramp-Up时间(秒): 1
- 循环次数: 1
- 线程组1 - 添加 - 取样器 - HTTP请求1
- HTTP请求1 - 添加 - 后置处理器 - XPath提取器
- Use Tidy: 勾选
- 引用名称: val
- XPath Query:
//title - 匹配数字【0代表随机,-1代表所有】: -1
- 缺省值: future-weaver
- 线程组1 - 添加 - 取样器 - BeanShell取样器
脚本:${__setProperty(out, ${val}, )}
- 测试计划 - 添加 - 线程(用户) - 线程组2
使用初始设置即可线程数: 1Ramp-Up时间(秒): 1循环次数: 1
- 线程组2 - 添加 - 取样器 - HTTP请求2
https://www.baidu.com/s?wd=${__property(out)}
- 测试计划 - 添加 - 监听器 - 察看结果树
高并发
同一时刻100个用户访问系统,统计高并发情况下平均响应时间以及错误率
- 测试计划 - 添加 - 线程 - 线程组
- 线程组 - 添加 - 取样器 - HTTP请求
http://localhost:8080/api/department
- HTTP请求 - 添加 - 定时器 - 同步定时器
模拟用户组的数量: 100超时时间(以毫秒为单位)【0为无限等待,否则为限时等待】: 10
- 测试计划 - 添加 - 监听器 - 聚合报告
高频率
一个用户以20QPS(20次/s)的频率访问学生管理系统,持续15秒,统计服务器的平均响应时间
QPS: Query per Seconds 每秒查询数(查询率)
- 测试计划 - 添加 - 线程 - 线程组
循环次数: 300(20qps x 15s)
- 线程组 - 添加 - 取样器 - HTTP请求
http://localhost:8080/api/department
- HTTP请求 - 添加 - 定时器 - 常数吞吐量定时器
- 目标吞吐量(每分钟的样本量): 1200
- 测试计划 - 添加 - 监听器 - 聚合报告
分布式
角色划分
- 控制机
负责任务分配
- 执行机
负责任务实现
工作流程
- 控制机需要制定测试任务,并下发到执行机
- 执行机执行任务并将结果返回给控制机
- 控制机做结果汇总
控制机配置
%JMETER_HOME%/bin/jmeter.properties
properties
remote_hosts=localhost:1099,localhost:2010
server.rmi.ssl.disable=true执行机配置
%JMETER_HOME%/bin/jmeter.properties
properties
server_port=1099
server.rmi.ssl.disable=true控制机发布任务
注意
需要将控制机和执行机全部启动
- 其他同理
- 运行按钮不再点
- 菜单 - 运行 - 远程启动所有
生成图形化报告
-e, 生成测试报告 -n, 以非图形模式运行 JMeter -t, 测试计划文件的路径和名称(jmx) -l, 指定保存结果文件(jtl) -j, 用于指定保存日志文件的位置(log) -g, 将 JTL 文件作为输入,然后 JMeter 将根据这些结果数据生成 HTML 格式的聚合报告。 -o, 指定报告输出目录,以html文件存在
生成html测试报告
以下命令运行结束后,可在目录中查看测试报告
shell
jmeter -n -t x.jmx -l x.log -e -o 目录JSON实战
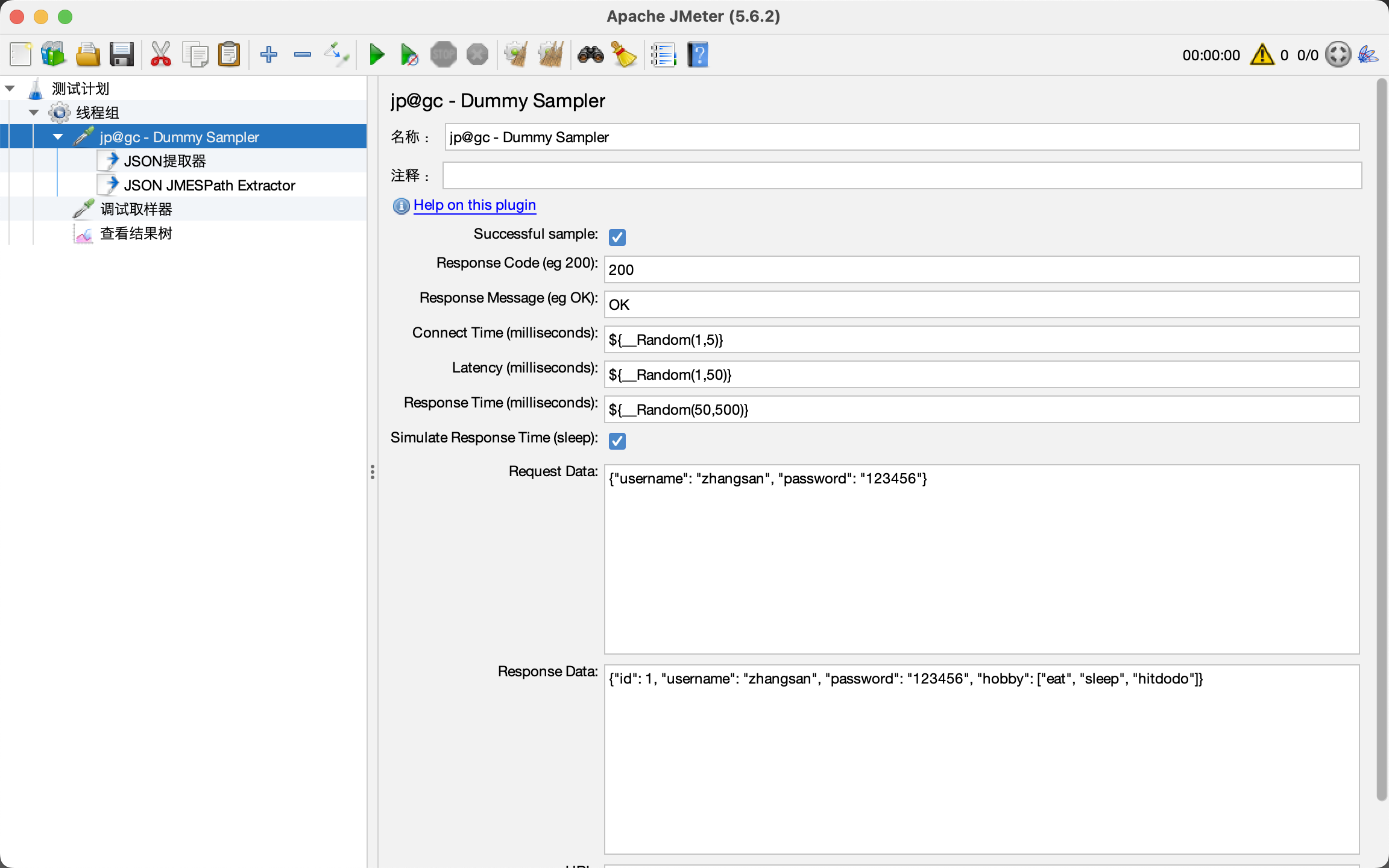
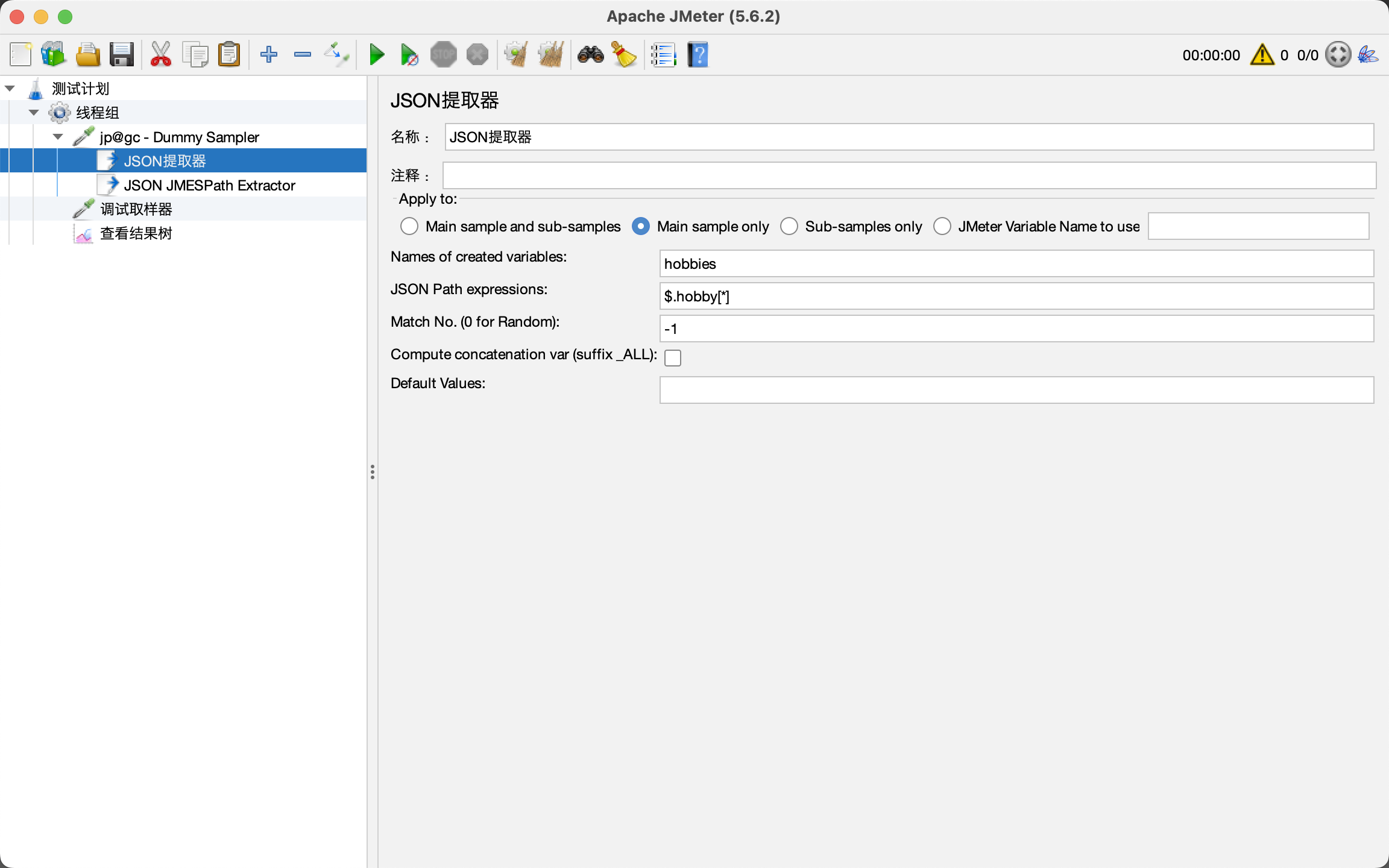
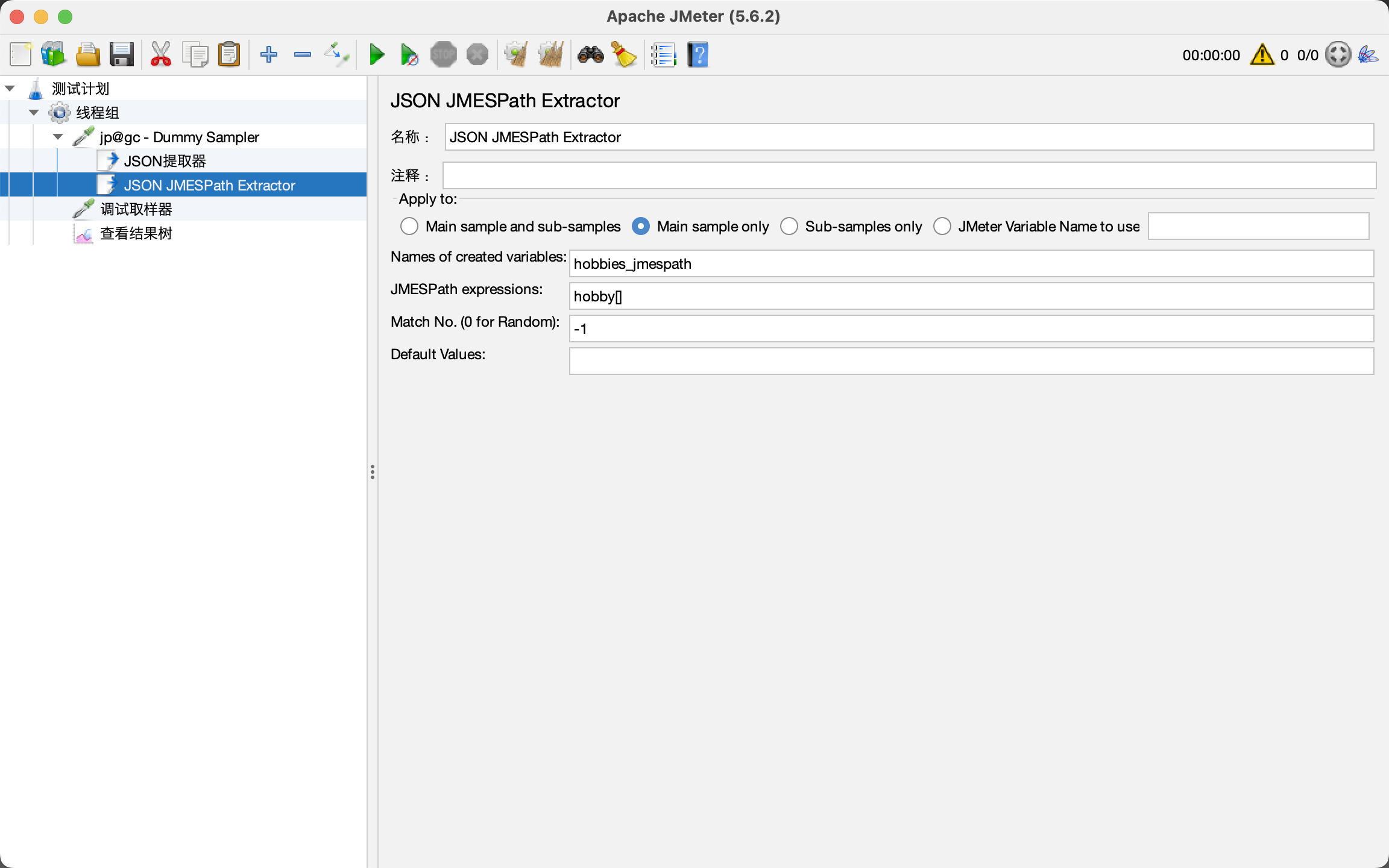
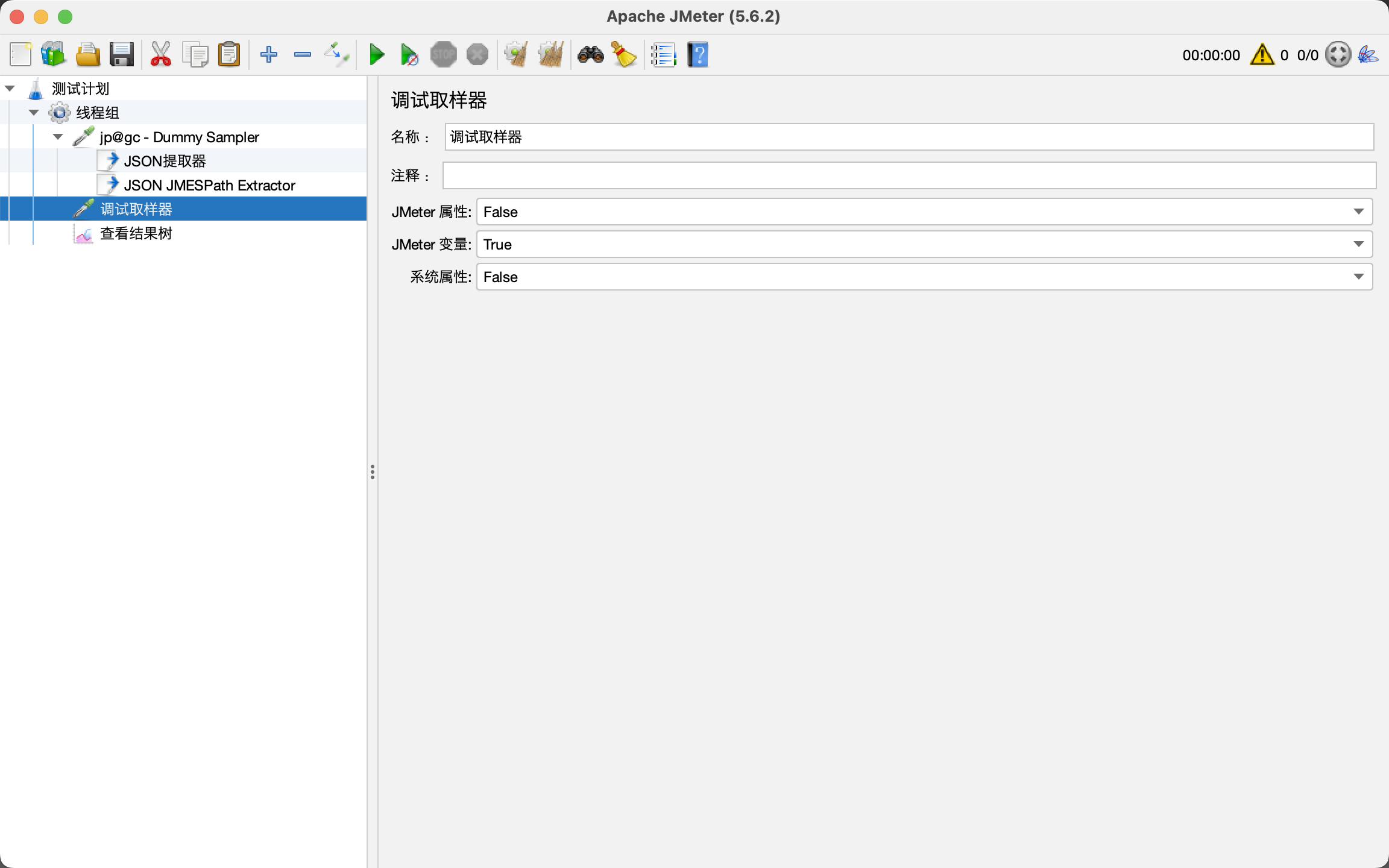

XPath实战
XPath2实战
下载文件实战
- 测试计划 - 添加jar包 -
commons-io.jar - 测试计划 - 添加 - 线程 - 线程组
- 线程组 - 添加 - 取样器 - HTTP请求
- HTTP请求 - 添加 - 后置处理器 - BeanShell后置处理器java
import org.apache.commons.io.IOUtils; import java.io.*; InputStream in = new ByteArrayInputStream(data); OutputStream out = new FileOutputStream("/Users/LEAF/Downloads/download.png"); IOUtils.copy(in, out); - 测试计划 - 添加 - 监听器 - 察看结果树
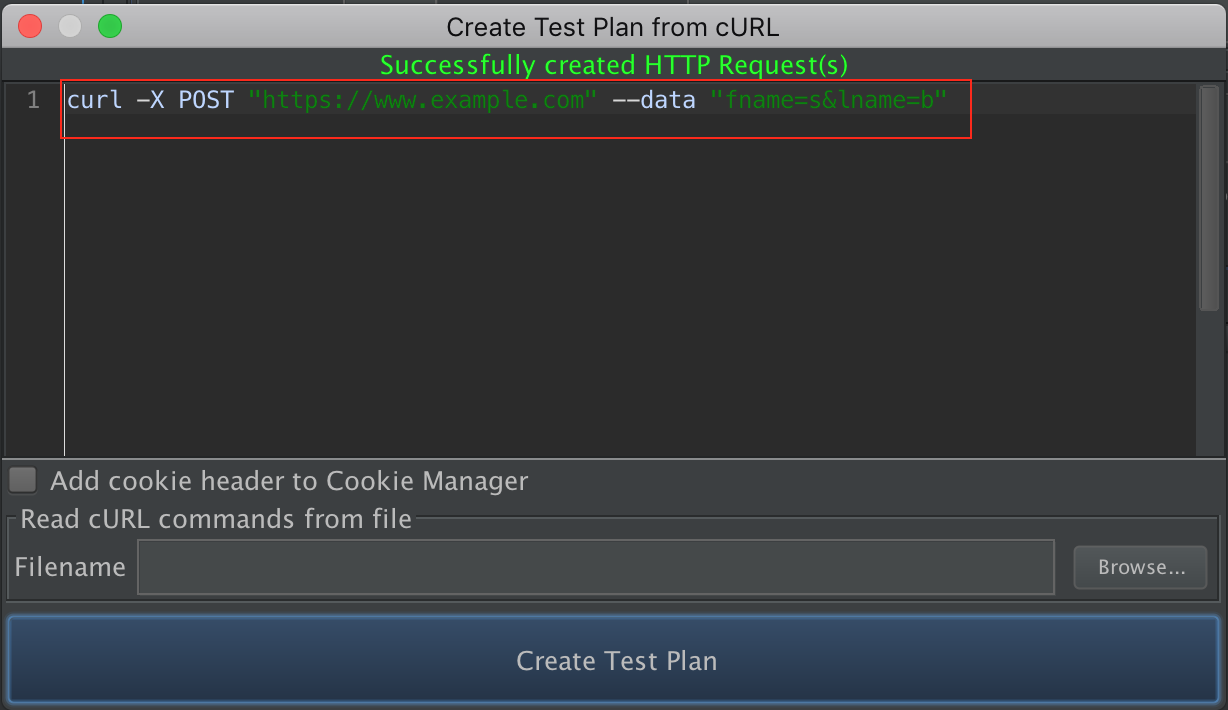
curl实战
Tools -> Import from cURL
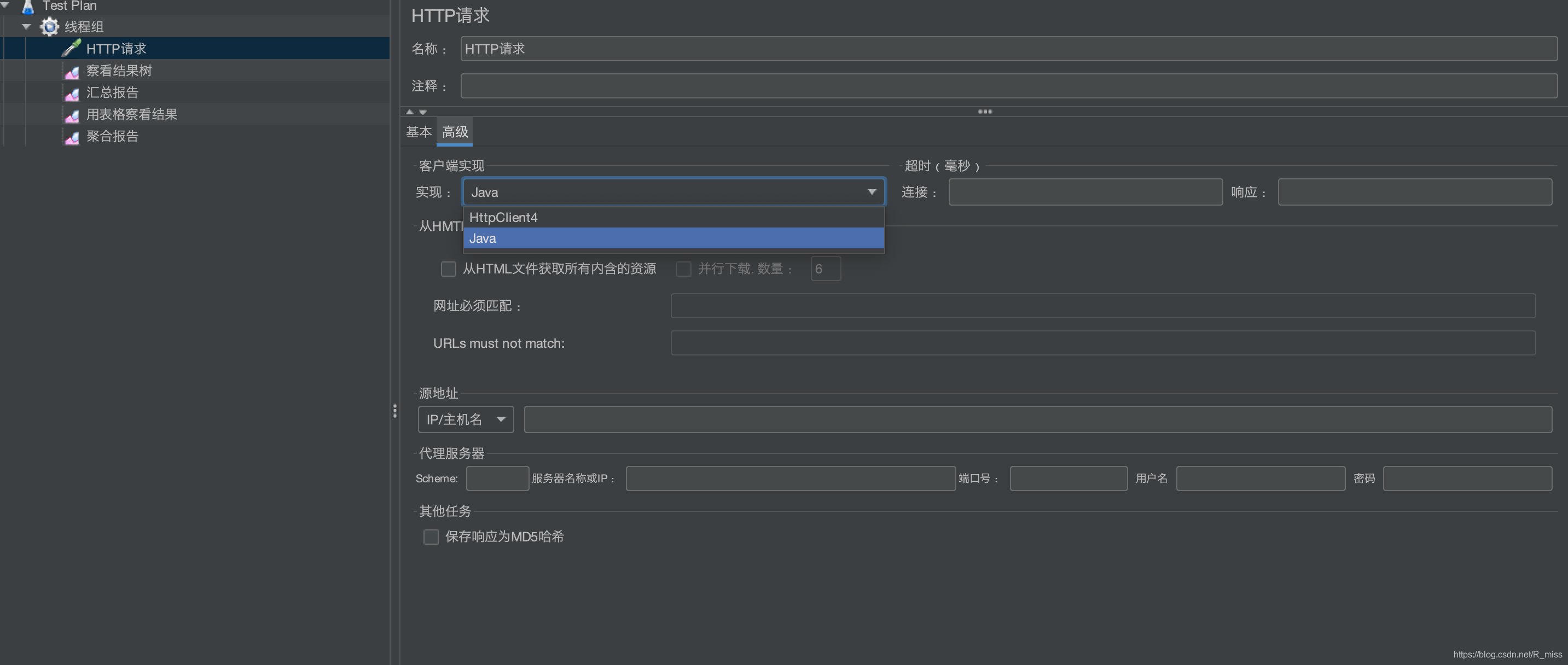
HttpHostConnectException异常的处理
HTTP请求 - 高级 - 客户端实现 - Java
学习目标总结
- 能掌握JMeter的逻辑控制器
- 能掌握JMeter的关联操作
- 能掌握JMeter的跨越线程组关联
- 能掌握JMeter高并发场景的设置
- 能掌握JMeter高频率场景的设置
- 能知道JMeter的分布式原理