Appearance
mysql深入
【重点】SQL约束
对表中的数据进行进一步的限制,保证数据的正确性、有效性和完整性。
约束种类:
PRIMARY KEY主键约束
UNIQUE唯一约束
NOT NULL非空约束
AUTO_INCREMENT自增约束
DEFAULT默认值
FOREIGN KEY外键约束
主键约束
用来唯一标识一条记录。
sql
CREATE TABLE tablename (
column_name datatype PRIMARY KEY
);sql
ALTER TABLE tablename ADD PRIMARY KEY(column_name)sql
ALTER TABLE tablename DROP PRIMARY KEY唯一约束
字段的值不能重复
sql
CREATE TABLE tablename (column_name datatype UNIQUE)sql
ALTER TABLE tablename ADD UNIQUE(column_name)sql
ALTER TABLE tablename DROP INDEX index_name非空约束
这个字段必须设置值,不能是NULL
sql
CREATE TABLE tablename(COLUMN datatype NOT NULL)sql
ALTER TABLE tablename MODIFY COLUMN column_name datatype NOT NULL自增约束
每次插入新记录时,数据库自动生成主键字段的值。
sql
CREATE TABLE tablename (column_name datatype PRIMARY KEY AUTO_INCREMENT)sql
ALTER TABLE tablename MODIFY COLUMN column_name INT(11) NOT NULL [AUTO_INCREMENT]sql
ALTER TABLE tablename AUTO_INCREMENT = value;默认约束
往表中添加数据时,如果不指定这个字段的数据,就使用默认值
sql
CREATE TABLE tablename (column_name datatype DEFAULT literal)sql
ALTER TABLE tablename ALTER COLUMN column_name SET DEFAULT literalsql
ALTER TABLE tablename ALTER COLUMN column_name DROP DEFAULT外键约束
sql
CREATE TABLE tablename (..., FOREIGN KEY(column_name) REFERENCES table_name(column_name))sql
ALTER TABLE tablename ADD FOREIGN KEY(column_name) REFERENCES table_name(column_name)sql
ALTER TABLE tablename DROP FOREIGN KEY fk_symbol【重点】表关系设计
在真实的开发中,一个项目中的数据一般都会保存在同一个数据库里,但是不同的数据需要保存在同一个数据库中,不同的数据表中。
在设计保存数据的数据表时,就需要根据具体的数据进行具体的分析,把同一类数据保存在同一张表,不同的数据保存在不同的表。所以不同表中的数据,就必然有一定的关联。这就需要在设计表时,考虑不同表之间的具体关系。
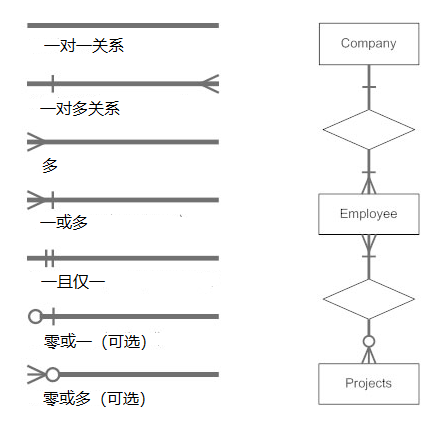
在数据库中,表总共存在三种关系:
- 一对一关系
- 一对多关系
- 多对多关系
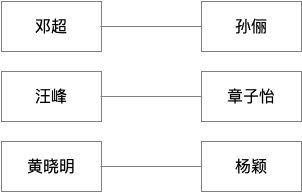
一对一
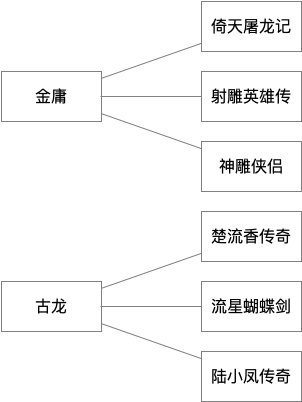
一对多
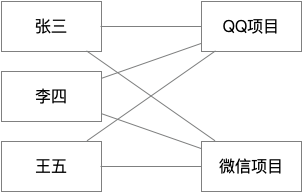
多对多
E-R图
外键约束(掌握)
创建第三张关系表即中间表,来维护程序员表和项目表之间的关系。
使用中间表的目的是维护两表多对多的关系:
中间表插入的数据,必须在多对多的主表中存在。
如果主表的记录在中间表维护了关系,就不能随意删除。如果可以删除,中间表就找不到对应的数据了,这样就没有意义了。
上述是中间表存在的意义,可是我们这里所创建的中间表并没有起到上述的作用,而是存在缺点的:
缺点 1: 我们是可以向中间表插入不存在的项目编号和程序员编号的。
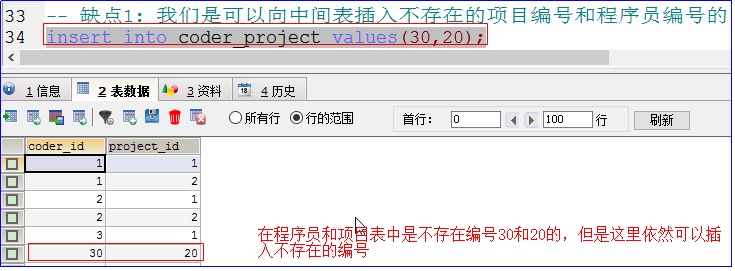
说明:在程序员和项目表中是不存在编号是 30 和 20 的,但是这里依然可以插入不存在的编号。这样做是不可以的,失去了中间表的意义。
缺点 2 : 如果中间表存在程序员的编号, 我们是可以删除程序员表对应的记录的。
在中间表中是存在编号为 1 的程序员的:
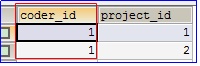
可是我们却可以删除程序员表 coder 中的编号为 1 的程序员:
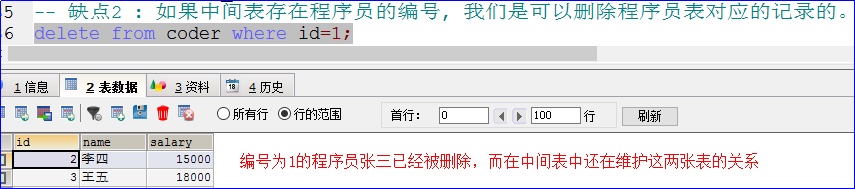
编号为 1 的程序员张三已经被我们删除,但是在中间表 coder_project 中仍然还存在编号为 1 的程序员,这样对于中间表没有意义了。
说明:
创建第三张表的语句:
sql
create table coder_project(
coder_id int ,--这个外键来自于coder表中的主键
project_id int--这个外键来自于project表中的主键
);我们在创建第三张关系表时,表中的每一列,都是在使用其他两张表中的列,这时我们需要对第三张表中的列进行相应的约束。
当前第三张表中的列由于都是引用其他表中的列,我们把第三张表中的这些列称为引用其他表的外键约束。
给某个表中的某一列添加外键约束:
简化语法:
sql
foreign key( 当前表中的列名 ) references 被引用表名(被引用表的列名);注意:一般在开发中,被引用表的列名都是被引用表中的主键。
举例:
sql
constraint [外键约束名称] foreign key(当前表中的列名) references 被引用表名(被引用表的列名)
举例:constraint coder_project_id foreign key(coder_id) references coder(id);关键字解释: constraint: 添加约束,可以不写 foreign key(当前表中的列名): 将某个字段作为外键 references 被引用表名(被引用表的列名) : 外键引用主表的主键
给第三张表添加外键约束有两种方式:
第一种方式:给已经存在的表添加外键约束:
sql
-- 来自于程序员表
alter table coder_project add constraint c_id_fk foreign key(coder_id) references coder(id);
-- 来自于项目表
alter table coder_project add constraint p_id_fk foreign key(project_id) references project(id);第二种方式:创建表时就添加外键约束:
sql
create table coder_project(
coder_id int,
project_id int,
constraint c_id_fk foreign key(coder_id) references coder(id),
constraint p_id_fk foreign key(project_id) references project(id)
);了解完如何给第三张表添加外键约束以后,我们就开始给上述创建好的第三张表添加外键约束。
在添加外键约束之前,由于刚才已经修改了表中的数据,所以我们先清空三张表,然后在添加外键约束。
操作步骤:
1、清空上述三张表:

2、增加外键约束:

3、添加完外键约束以后,就会在可视化工具中的架构设计器上查看表之间的关系
先选中表
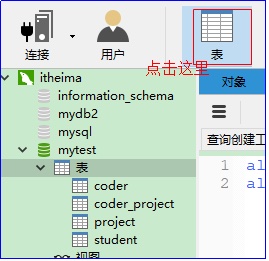
然后点击右下角:
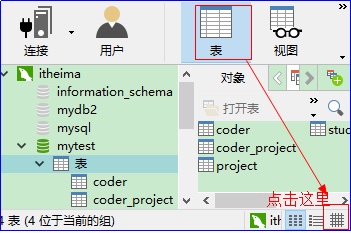
最后的表关系如下:

3、向三张表中分别插入数据:
sql
-- 插入数据
insert into coder values(null,'张三',12000);
insert into coder values(null,'李四',15000);
insert into coder values(null,'王五',18000);
insert into project values(null,'QQ项目');
insert into project values(null,'微信项目');
insert into coder_project values(1,1);
insert into coder_project values(1,2);
insert into coder_project values(2,1);
insert into coder_project values(2,2);
insert into coder_project values(3,1);4、测试外键约束是否起到作用:
A:执行以下语句:
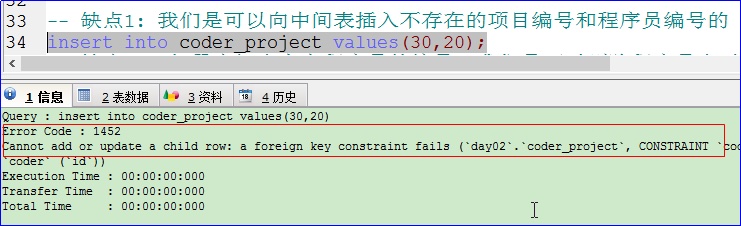
B:执行以下语句:
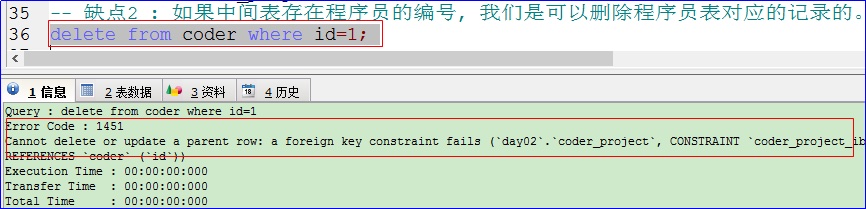
再次执行上述语句的时候,发现报错了,而数据库表中的数据都没有改变,说明外键约束起到了作用。
外键的级联(掌握)
在修改和删除主表的主键时,同时更新或删除从表的外键值,称为级联操作 ON UPDATE CASCADE -- 级联更新,主键发生更新时,外键也会更新 ON DELETE CASCADE -- 级联删除,主键发生删除时,外键也会删除
具体操作:
- 删除三张表 coder、coder_project、project 表
- 重新创建三张表,添加级联更新和级联删除
sql
-- 创建程序员表
create table coder(
id int primary key auto_increment,
name varchar(50),
salary double
);
-- 创建项目表
create table project(
id int primary key auto_increment,
name varchar(50)
);
create table coder_project(
coder_id int,
project_id int,
-- 添加外键约束,并且添加级联更新和级联删除
constraint c_id_fk foreign key(coder_id) references coder(id) ON UPDATE CASCADE ON DELETE CASCADE,
constraint p_id_fk foreign key(project_id) references project(id) ON UPDATE CASCADE ON DELETE CASCADE
);再次添加数据到三张表:
sql
-- 添加测试数据
insert into coder values(1,'张三',12000);
insert into coder values(2,'李四',15000);
insert into coder values(3,'王五',18000);
insert into project values(1,'QQ项目');
insert into project values(2,'微信项目');
insert into coder_project values(1,1);
insert into coder_project values(1,2);
insert into coder_project values(2,1);
insert into coder_project values(2,2);
insert into coder_project values(3,2);需求1:修改主表coder表的id为3变为4.
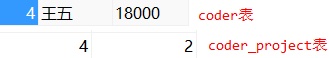
需求2:删除主表coder表的id是4的行数据。
小结:
级联更新:ON UPDATE CASCADE 主键修改后,外键也会跟着修改
级联删除:ON DELETE CASCADE 主键删除后,外键对应的数据也会删除
【扩展】范式
概念
好的数据库设计对数据的存储性能和后期的程序开发,都会产生重要的影响。建立科学的,规范的数据库就需要满足一些规则(Normal Form),来优化数据的设计。目前共定义了 6 种范式:
第一范式(1NF)
第二范式(2NF)
第三范式(3NF)
巴斯科德范式(BCNF)
第四范式(4NF)
第五范式(5NF)
在实际应用中,一般只需要达到 3NF。
函数依赖
如果通过 A 属性的值,可以唯一确定 B 属性的值,则称 B 函数依赖于 A。
通过学号,能够确定姓名
通过学号和课程名称,能够确定分数
完全函数依赖
如果 A 是一个属性组,想要唯一确定 B 属性的值,需要依赖 A 属性组中所有的属性值。
通过学号和课程名称,能够确定分数
部分函数依赖
如果 A 是一个属性组,想要唯一确定 B 属性的值,只需要依赖 A 属性组中某一些值即可。
(学号和课程名称组成的属性组中),只需学号,就能够确定姓名。
传递函数依赖
通过 A 属性的值,可以唯一确定 B 属性的值;通过 B 属性的值,可以唯一确定 C 属性的值。则称 C 传递依赖于 A
通过学号,能确定系名;通过系名,能确定系主任
候选码
一个属性或属性组,被其他所有属性所完全依赖,则称这个属性为该表的码。也称为键或关键字。
主属性
包含在任意一个候选码中的属性
非主属性
不包含在任何一个候选码中的属性
第一范式
官方描述
在关系模式R中,当且仅当所有属性只包含原子值,即每个分量都是不可再分的数据项,则称R满足1NF
指标
- 原子性
通俗理解
每一列不可拆分
姓名 市 区 街道 张三 上海市 浦东新区 航头镇 李四 上海市 浦东新区 周浦镇
第二范式
官方描述
当且仅当关系模式R满足1NF,且每个非键属性(即不属性任何候选键的属性,也称为非主属性)完全依赖于候选键时,则称R满足2NF。
指标
- 唯一性
通俗理解
必须有主键
每张表只描述一件事
- 地址表
id 市 区 街道 1 上海市 浦东新区 航头镇
- 用户表
id 姓名 1 张三 2 李四
第三范式
官方描述
当且仅当关系模式R满足1NF,且R中没有非键属性传递依赖于候选键时,则称R满足3NF。
指标
- 关联性
通俗理解
从表的外键必须使用主表的主键
- 用户表
姓名 id 地址 张三 1 1 李四 2 2
巴斯科德范式
官方描述
如果关系模式R满足1NF,且R中没有属性传递依赖于候选键时,则称R满足BCNF。
指标
- 完整性
- 一致性
通俗理解
借助中间表,实现多对多关系
第四范式
官方描述
将关系模式中的多值依赖拆分成单值依赖,从而避免数据冗余
指标
- 准确性
- 独立性
通俗理解
不要有冗余
第五范式
官方描述
在一个关系型数据库中,任何联接依赖都被消除。
指标
- 完整性
通俗理解
也被称为"投影-连接范式",或"完美范式"。
第五范式的主要目标是确保数据库设计可以支持所有可能的查询。或者说,为了满足第五范式,数据库设计师需要确保数据库的结构可以支持所有的业务需求,而不是简单地添加更多的表和列来存储冗余数据。
以有限的数据,实现无限的业务
【重点】高级查询
为什么需要有多表操作
准备数据
sql
-- 创建部门表
create table dept(
id int primary key auto_increment,
name varchar(20)
);
insert into dept (name) values ('开发部'),('市场部'),('财务部');
-- 创建员工表
create table emp (
id int primary key auto_increment,
name varchar(10),
gender char(1), -- 性别
salary double, -- 工资
join_date date, -- 入职日期
dept_id int,
foreign key (dept_id) references dept(id) -- 外键,关联部门表(部门表的主键)
);
insert into emp(name,gender,salary,join_date,dept_id) values('孙悟空','男',7200,'2013-02-24',1);
insert into emp(name,gender,salary,join_date,dept_id) values('猪八戒','男',3600,'2010-12-02',2);
insert into emp(name,gender,salary,join_date,dept_id) values('唐僧','男',9000,'2008-08-08',2);
insert into emp(name,gender,salary,join_date,dept_id) values('白骨精','女',5000,'2015-10-07',3);
insert into emp(name,gender,salary,join_date,dept_id) values('蜘蛛精','女',4500,'2011-03-14',1);查询某员工在哪个部门?
sql
-- 只查询一张表不能查询出员工名字和部门名字,需要使用多表操作
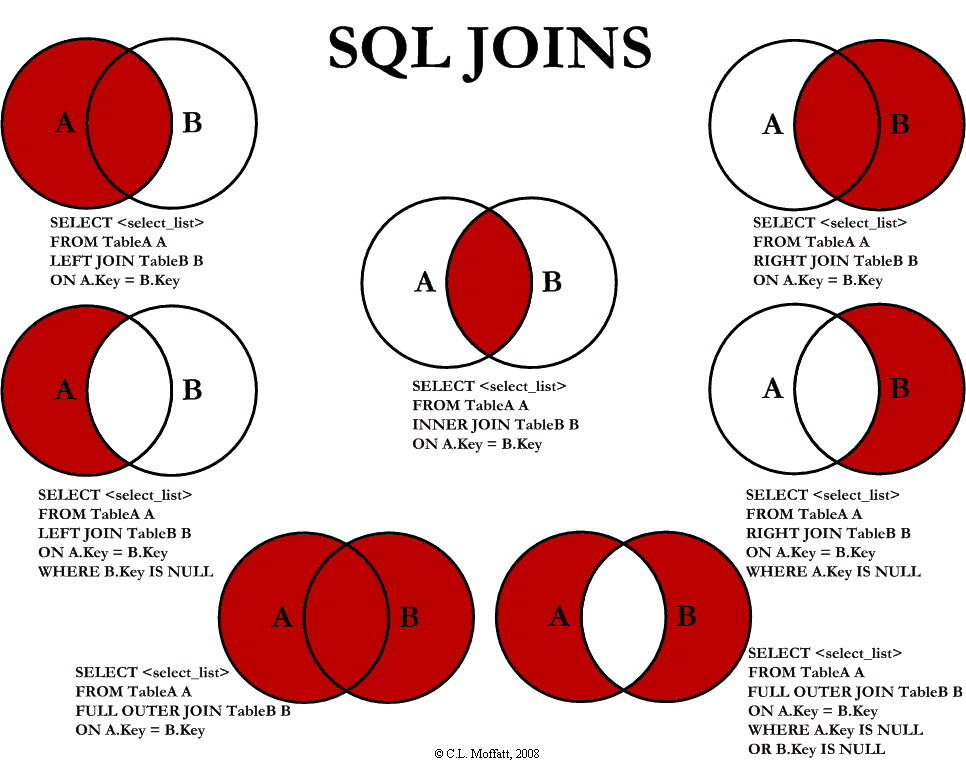
select * from emp, dept;完成多表操作的两种方式:
- 表连接
- 子查询
笛卡尔积
概念
左表的每条数据和右表的每条数据组合成新的数据
如:查询员工表和部门表,查询的数据如下,结果就是笛卡尔积的数据
sql
select * from emp,dept;查询某员工所在的部门
部门是左表,员工是右表。
我们发现不是所有的数据组合都是有用的,只有员工表.dept_id = 部门表.id 的数据才是有用的。所以需要通过条件过滤掉没用的数据
sql
-- 1. 查询孙悟空在哪个部门名字
select * from emp;
select * from dept;
-- 2. 查询所有的员工和所有的部门
-- 查询2张表结果是2张表记录的乘积,称为笛卡尔积
select * from emp,dept;
- 如何消除笛卡尔积:条件是从表.外键=主表.主键
select * from emp,dept where emp.dept_id = dept.id;
-- 这就是隐式内连接,使用where,没有用到join...on
-- 给表起别名
select * from emp e ,dept d where e.dept_id = d.id;
-- 查询孙悟空在哪个部门名字
select * from emp e ,dept d where e.dept_id = d.id and e.id=1;
-- 只查询孙悟空的员工名字和部门名字,并指定别名:员工名、部门名
select e.name 员工名,d.name 部门名 from emp e ,dept d where e.dept_id = d.id and e.id=1;内连接
内连接分类
隐式内连接
显示内连接
语法
sql
-- 隐式内连接语法
select 列名 from 左表,右表 where 从表.外键=主表.主键
-- 显示内连接, on后面就是表连接的条件
select 列名 from 左表 inner join 右表 on 从表.外键=主表.主键应用
查询唐僧的信息,显示员工 id,姓名,性别,工资和所在的部门名称
- 确定查询哪些表
- 确定表连接条件,员工表.dept_id = 部门表.id 的数据才是有效的
- 确定查询条件,我们查询的是唐僧的信息,员工表.name='唐僧'
- 确定查询字段,查询唐僧的信息,显示员工 id,姓名,性别,工资和所在的部门名称
- 我们发现写表名有点长,可以给表取别名,显示的字段名也使用别名
sql
-- 查询唐僧的信息,显示员工id,姓名,性别,工资和所在的部门名称
-- 1. 确定查询哪些表
select * from emp e inner join dept d;
-- 2. 确定表连接的条件
select * from emp e inner join dept d on e.dept_id = d.id;
-- 3. 如果有其它的查询条件,添加where语句
select * from emp e inner join dept d on e.dept_id = d.id where e.name='唐僧';
-- 4. 确定查询哪些列
select e.id 编号, e.name 姓名, e.gender 性别, e.salary 工资, d.name 部门名
from emp e inner join dept d on e.dept_id = d.id where e.name='唐僧';外连接
外连接分类
左外连接
左表中所有的记录都出现在结果中,如果右表没有匹配的记录,使用 NULL 填充
右外连接
右表中所有的记录都出现在结果中,如果左表没有对应的记录,使用 NULL 填充
语法
sql
-- 左外连接,左表中所有的记录都出现在结果,如果右表没有匹配的记录,使用NULL填充
select 列名 from 左表 left join 右表 on 从表.外键=主表.主键
-- 右外连接,保证右表中所有的数据都出现,如果左表没有对应的记录,使用NULL填充
select 列名 from 左表 right join 右表 on 从表.外键=主表.主键应用
左外连接
需求:查询所有的部门,以及该部门下面的员工
sql
-- 添加一个销售部,暂时还没有员工
insert into dept (name) values ('销售部');
-- 使用内连接查询,缺少销售部
select * from dept d inner join emp e on d.id = e.dept_id;
-- 使用左外连接查询
select * from dept d left join emp e on d.id = e.dept_id;右外连接
需求:查询所有员工,以及员工所属的部门
sql
-- 在员工表中增加一个员工:'沙僧','男',6666,'2013-02-24',null
insert into emp values(null, '沙僧','男',6666,'2013-02-24',null);
select * from emp;
-- 使用内连接查询
select * from dept d inner join emp e on d.id = e.dept_id;
-- 使用右外连接查询
select * from dept d right join emp e on d.id = e.dept_id;子查询
什么是子查询
- 将一个查询的结果做为另一个查询的条件
- 这是一种查询语句的嵌套,嵌套的 SQL 查询称为子查询。
- 如果使用子查询必须要使用括号
子查询分类
- 单行单列
- 单行多列
- 多行多列
单行单例
语法
sql
-- 如果子查询是单行单列,父查询使用比较运算符:> < =应用
sql
-- 1. 查询最高工资是多少
select max(salary) from emp;
-- 2. 查询最高工资的员工信息
select * from emp where salary=(select max(salary) from emp);
-- 查询工资大于"蜘蛛精"的员工
-- 1. 查询蜘蛛精的工资是多少
select salary from emp where name='蜘蛛精';
-- 2. 查询大于这个工资的员工
select * from emp where salary > (select salary from emp where name='蜘蛛精');多行单列
语法
多行单列认为是一个数组,父查询使用in、any 、all关键字
| 关键字 | 说明 |
|---|---|
| in | 查询包含在in条件中的所有数据 |
| all | 可以与>、<结合起来使用,分别表示大于、小于其中的所有数据时条件为真 |
| any | 可以与>、<结合起来使用,分别表示大于、小于其中的任何一个数据时条件为真 |
应用
sql
-- 查询工资大于5000的员工,来自于哪些部门,得到部门的名字
-- 1. 先查询大于5000的员工所在的部门id
select dept_id from emp where salary > 5000;
-- 2. 再查询在这些部门id中部门的名字
select * from dept where id in (select dept_id from emp where salary > 5000);
-- 查询工资高于在1号部门工作的所有员工的员工信息
-- 1. 查询1号部门所有员工的工资,得到多行单列
select salary from emp where dept_id=1;
-- 2. 使用all关键字
select * from emp where salary > all (select salary from emp where dept_id=1);
-- 查询工资高于在1号部门工作的所有员工最低工资的员工信息
-- 1. 查询1号部门所有员工的工资,得到多行单列
select salary from emp where dept_id=1;
-- 2. 使用any关键字
select * from emp where salary > any (select salary from emp where dept_id=1);多行多列
特点
子查询可以认为它是一张虚拟表,可以使用表连接再次进行多表查询
如果访问子查询表的字段,需要为子查询表取别名,否则无法访问表中的字段
应用
sql
-- 查询出2011年以后入职的员工信息,包括部门名称
-- 1. 在员工表中查询2011-1-1以后入职的员工
select * from emp where join_date > '2011-1-1';
-- 2. 查询所有的部门信息,与上面的虚拟表中的信息组合,找出所有部门id等于的dept_id
select * from dept d inner join (select * from emp where join_date > '2011-1-1') e on d.id = e.dept_id;
-- 3. 使用右连接,否则没有部门的员工信息查询不到
select * from dept d right join (select * from emp where join_date > '2011-1-1') e on d.id = e.dept_id;【重点】索引
概述
索引,是数据库中专门用于帮助用户快速查询数据的一种数据结构,类似于字典中的目录
索引是表的目录,在查找内容之前可以先在目录中查找索引位置,以此快速定位查询数据。对于索引,会保存在额外的文件中
索引建立的原则
表的主键、外键必须有索引;外键是唯一的,而且经常会用来查询
数据量超过 300 的表应该有索引
经常与其他表进行连接的表,在连接字段上应该建立索引;经常连接查询,需要有索引
经常出现在 Where 子句中的字段,加快判断速度,特别是大表的字段,应该建立索引。
注意: 建引,一般用在select ……where f1 and f2 ,我们在f1或者f2上建立索引是没用的。只有两个使用联合索引才能有用
经常用到排序的列上,因为索引已经排序
经常用在范围内搜索的列上创建索引,因为索引已经排序了,其指定的范围是连续的
常用索引分类
| 索引分类 | 作用 |
|---|---|
| 普通索引 | 仅加速查询 最基本的索引,没有任何限制, 大多数情况下使用到的索引 |
| 唯一索引 | 加速查询 + 列值唯一(可以有null) |
| 组合索引 | 将几个列作为一条索引进行检索, 使用最左匹配原则,即一定要包含最左边的 |
语法
创建索引
sql
-- 建表时创建索引
create table 表名 (
字段名1 字段类型1,
字段名2 字段类型2,
[unique] index (字段名1 [, 字段名2])
);
-- 表创建后再创建索引
create [unique] index 索引名称 on 表名 (字段名1 [, 字段名2]);删除索引
sql
drop index 索引名称 on 表名;
alter table 表名 drop index 索引名称;查看表中的索引
sql
show index from 表名;代码
sql
/*
* 新建订单表user_order
* id 编号,自增主键
* uid 用户id 整型
* createtime 订单创建时间 日期
* pid 产品id 整型
* price 产品价格 decimal
* pname 产品名称 可变字符串100
* uid和pid是组合索引
*/
-- 导入数据
-- 创建组合索引(uid、pid)
-- 查询【重点】事务
概述
在实际的业务开发中,有些业务操作要多次访问数据库。一个业务要发送多条 SQL 语句给数据库执行。需要将多次访问数据库的操作视为一个整体来执行,要么所有的 SQL 语句全部执行成功。如果其中有一条 SQL 语句失败,就进行事务的回滚,所有的 SQL 语句全部执行失败。
事务的应用场景
张三给李四转账,张三账号减钱,李四账号加钱。
假设当张三账号上-500 元,服务器崩溃了。李四的账号并没有+500 元,数据就出现问题了。我们需要保证其中一条 SQL 语句出现问题,整个转账就算失败。只有两条 SQL 都成功了转账才算成功。这个时候就需要用到事务。
sql
-- 创建数据表
CREATE TABLE account (
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(10),
balance DOUBLE
);
-- 添加数据
INSERT INTO account (NAME, balance) VALUES ('张三', 1000), ('李四', 1000);
-- 1. 张三账号-500
UPDATE account SET balance = balance - 500 WHERE id=1;
-- 2. 李四账号+500
UPDATE account SET balance = balance + 500 WHERE id=2;事务的四大特性(ACID)
原子性(Atomicity)
事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生。
一致性(Consistency)
事务前后数据的完整性必须保持一致
隔离性(Isolation)
多个用户并发访问数据库时,一个用户的事务不能被其它用户的事务所干扰,多个并发事务之间数据要相互隔离,不能相互影响。
持久性(Durability)
事务一旦被提交,它对数据库中数据的改变就是永久性的,即使数据库发生故障也不应该对其有任何影响
事务控制
语法
START TRANSACTION开启事务
COMMIT提交事务
ROLLBACK回滚事务
事务控制流程
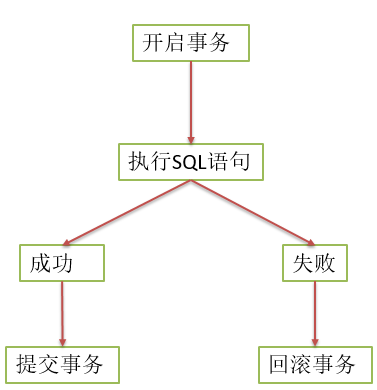
第 1 种情况:开启事务 -> 执行 SQL 语句 -> 成功 -> 提交事务 第 2 种情况:开启事务 -> 执行 SQL 语句 -> 失败 -> 回滚事务
演示【成功】
模拟张三给李四转500元钱
恢复数据
sqlUPDATE account SET balance = 1000;开启事务
sqlSTART TRANSACTION; UPDATE account SET balance = balance - 500 WHERE id=1; UPDATE account SET balance = balance + 500 WHERE id=2;查询数据库
sqlSELECT * FROM account;id NAME balance 1 张三 1000 2 李四 1000 提交事务
sqlCOMMIT;查询数据库
sqlSELECT * FROM account;id NAME balance 1 张三 500 2 李四 1500
演示【失败】
恢复数据
sqlUPDATE account SET balance = 1000;开启事务
sqlSTART TRANSACTION; UPDATE account SET balance = balance - 500 WHERE id=1;查询数据库
sqlSELECT * FROM account;id NAME balance 1 张三 1000 2 李四 1000 回滚事务
sqlROLLBACK;查询数据库
sqlSELECT * FROM account;id NAME balance 1 张三 1000 2 李四 1000
单条DML事务
MySQL 的每一条 DML(增删改)语句都是一个单独的事务,每条语句都会自动开启一个事务,执行完毕自动提交事务,MySQL 默认开始自动提交事务。
自动提交事务
恢复数据
sqlUPDATE account SET balance = 1000;更新张三帐号
sqlUPDATE account SET balance = balance - 500 WHERE id=1;查看数据库
sqlSELECT * FROM account;id NAME balance 1 张三 500 2 李四 1000 查看
autocommit全局变量sqlSHOW VARIABLES LIKE '%commit%'; -- 或 SELECT @@autocommit; -- 0:OFF(关闭自动提交) -- 1:ON(开启自动提交)
手动提交事务
恢复数据
sqlUPDATE account SET balance = 1000;修改全局变量"autocommit",取消自动提交事务
sqlSET autocommit=0;更新张三帐号
sqlUPDATE account SET balance = balance - 500 WHERE id=1;查看数据库
数据未改变
sqlSELECT * FROM account;id NAME balance 1 张三 1000 2 李四 1000 提交事务
sqlCOMMIT;查看数据库
数据已改变
sqlSELECT * FROM account;id NAME balance 1 张三 500 2 李四 1000
事务原理
事务开启之后, 所有的操作都会临时保存到事务日志, 事务日志只有在得到commit命令才会同步到数据表中,其他任何情况都会清空事务日志(rollback,断开连接) 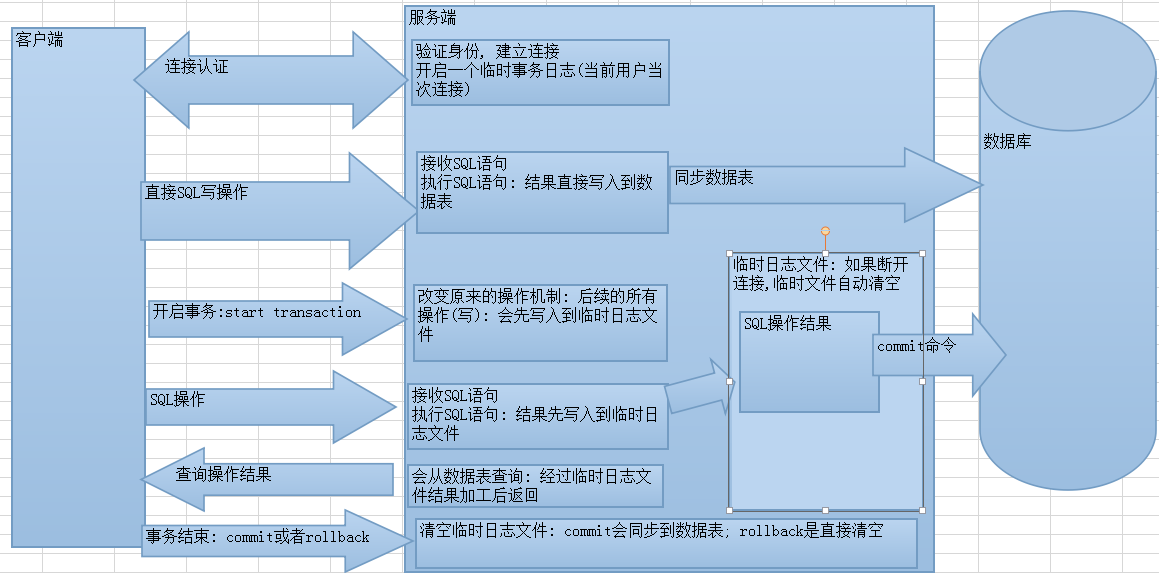
小结
说出事务原理? 开启事务后,SQL 语句会放在临时的日志文件,如果提交事务,将日志文件中 SQL 的结果放在数据库中
如果回滚事务清空日志文件.
| 事务的操作 | MySQL操作事务的语句 |
|---|---|
| 开启事务 | start transaction |
| 提交事务 | commit |
| 回滚事务 | rollback |
| 查询事务的自动提交情况 | show variables like '%commit%'; / select @@autocommit; |
| 设置事务的自动提交方式 | set autocommit = 0 -- 关闭自动提交 |
【扩展】并发访问
并发访问的问题
理想状态下,在操作事务时,多个事务之间互不影响。
如果隔离级别设置不当就可能引发并发访问问题:
脏读
一个事务读取到了另一个事务中尚未提交的数据

不可重复读
一个事务中两次读取的数据内容不一致,要求的是一个事务中多次读取时数据是一致的,这是事务update时引发的问题

幻读
一个事务内读取到了别的事务插入的数据,导致前后读取记录行数不同。这是insert或delete时引发的问题
事务隔离级别
MySQL 数据库有四种隔离级别:上面的级别最低,下面的级别最高。
| 级别 | 名字 | 隔离级别 | 脏读 | 不可重复读 | 幻读 | 数据库默认隔离级别 |
|---|---|---|---|---|---|---|
| 1 | 读未提交 | read uncommitted | 是 | 是 | 是 | |
| 2 | 读已提交 | read committed | 否 | 是 | 是 | Oracle和SQL Server |
| 3 | 可重复读 | repeatable read | 否 | 否 | 是 | MySQL |
| 4 | 串行化 | serializable | 否 | 否 | 否 |
脏读
脏读非常危险的,比如张三向李四购买商品,张三开启事务,向李四账号转入500块,然后打电话给李四说钱已经转了。李四一查询钱到账了,发货给张三。张三收到货后回滚事务,李四的再查看钱没了。
演示
查询全局事务隔离级别
sqlshow variables like '%isolation%'; select @@tx_isolation;设置事务隔离级别,需要退出 MSQL 再进入 MYSQL 才能看到隔离级别的变化
sqlset global transaction isolation level read uncommitted;sqlUPDATE account SET balance = 1000;打开 A 窗口登录 MySQL,设置全局的隔离级别为最低
sqlmysql -u root -p set global transaction isolation level read uncommitted;打开 B 窗口,AB 窗口都开启事务
sqluse day23; start transaction;【A 窗口】更新 2 个人的账户数据,未提交
sqlupdate account set balance=balance-500 where id=1; update account set balance=balance+500 where id=2;【B 窗口】查询账户
sqlselect * from account;id NAME balance 1 张三 500 2 李四 1500 A 窗口回滚
sqlrollback;B 窗口查询账户,钱没了
sqlSELECT * FROM account;id NAME balance 1 张三 1000 2 李四 1000
解决方案
提升全局隔离级别为
read committed
恢复数据
sqlUPDATE account SET balance = 1000;设置全局隔离级别为
read committedsqlset global transaction isolation level read committed;
不可重复读
两次查询输出的结果不同,到底哪次是对的?不知道以哪次为准。
很多人认为这种情况就对了,无须困惑,当然是后面的为准。我们可以考虑这样一种情况,比如银行程序需要将查询结果分别输出到电脑屏幕和发短信给客户,结果在一个事务中针对不同的输出目的地进行的两次查询不一致,导致文件和屏幕中的结果不一致,银行工作人员就不知道以哪个为准了。
演示
恢复数据
sqlUPDATE account SET balance = 1000;设置全局隔离级别
sqlset global transaction isolation level read committed;【B 窗口】开启事务,查询数据
sqlstart transaction; select * from account;id NAME balance 1 张三 1000 2 李四 1000 【A 窗口】开启事务,更新数据
sqlstart transaction; update account set balance=balance+500 where id=1; commit;【B 窗口】查询
sqlselect * from account;id NAME balance 1 张三 1000 2 李四 1000
解决方案
提升全局隔离级别为
repeatable read
恢复数据
sqlUPDATE account SET balance = 1000;设置全局隔离级别为
repeatable readsqlset global transaction isolation level repeatable read;
幻读
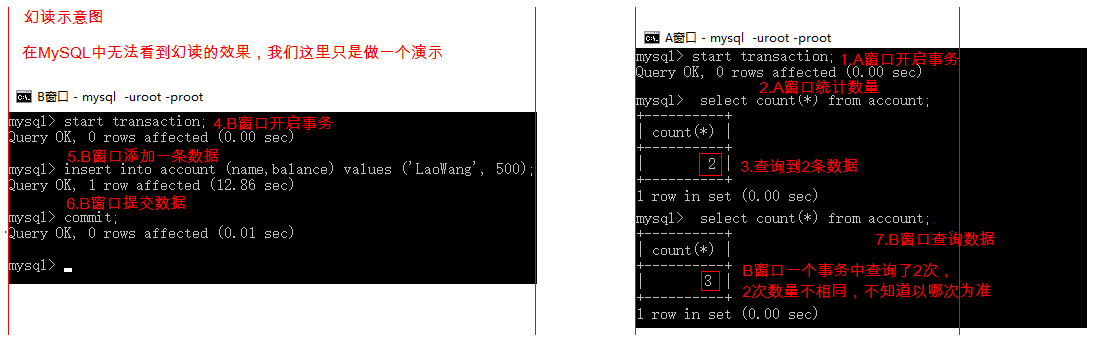
是指在一个事务内读取到了别的事务插入的数据,导致前后读取记录行数不同。这是insert或delete时引发的问题
演示
【A 窗口】开启事务,查询 id>1 的数据
sqlSTART TRANSACTION; SELECT * FROM account WHERE id > 1;id NAME balance 2 李四 1000 【B 窗口】开启事务,添加一条数据,提交事务
sqlSTART TRANSACTION; INSERT INTO account(NAME, balance) VALUES('tom', 22000); COMMIT;【A 窗口】修改 id>1balance 为 0,重新查询 id>1 的数据
sqlUPDATE account SET balance=0 WHERE id > 1; SELECT * FROM account WHERE id > 1;id NAME balance 1 李四 0 2 tom 0
解决方案
提升全局隔离级别为serializable
恢复数据
sqlUPDATE account SET balance = 1000;设置全局隔离级别为
serializablesqlset global transaction isolation level `serializable`;
小结
并发访问的三个问题
- 赃读
一个事务读取另一个事务还没有提交的数据
- 不可重复读
一个事务读取多次数据内容不一样
- 幻读
一个事务读取多次数量不一样
四种隔离级别
- 读未提交(read uncommitted)
- 读已提交(read committed)
- 可重复读(repeatable read)
- 串行化(serializable)
【扩展】事务的传播特性
PROPAGATION_REQUIRED
如果存在活动事务,⽀持当前事务。 如果没有活动事务,则开启
PROPAGATION_SUPPORTS(propagation_supports)
如果存在活动事务,支持当前事务。 如果没有活动事务,则非事务执⾏
PROPAGATION_MANDATORY(propagation_mandatory)
如果存在活动事务,支持当前事务。 如果没有活动事务,则抛出异常
PROPAGATION_REQUIRES_NEW(propagation_requires_new)
总是开启一个新的事务。 如果存在活动事务,则将这个存在的事务挂起
PROPAGATION_NOT_SUPPORTED(propagation_not_supported)
总是非事务执⾏,并挂起任何存在的事务。
PROPAGATION_NEVER(propagation_never)
总是非事务执⾏ 如果存在活动事务,则抛出异常
PROPAGATION_NESTED(propagation_nested)
如果存在活动事务,则运⾏在一个嵌套的事务中; 如果没有活动事务,则按PROPAGATION_REQUIRED属性执⾏
学习目标总结
- 能够使用 SQL 语句添加主键、外键、唯一、非空约束
- 能够说出多表之间的关系及其建表原则
- 能够理解三大范式
- 能够使用内连接进行多表查询
- 能够使用外连接进行多表查询
- 能够使用子查询进行多表查询
- 能够理解多表查询的规律
- 能够理解事务的概念
- 能够说出事务的原理
- 能够在 MySQL 中使用事务
- 能够理解脏读,不可重复读,幻读的概念及解决办法